前言
如果有了解過 SEO ,那你可能有聽說過『 robots.txt 』這個名字。
主要用來避免網站要求太多,導致超載(要求太多會人家討厭的
而簡單來說,他就是來讓爬蟲程式聽話的一個檔案,像是該爬這裡、不該走這裡,
但是但是但是…有機率會不聽話失效🤫。
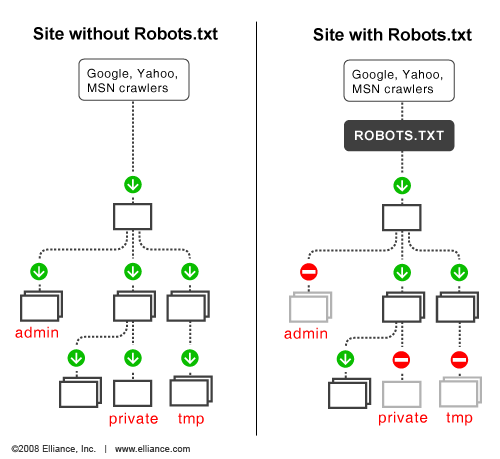
建議使用的理由
robots.txt 檔案主用途在於管理爬蟲對自己網站的流量,直接了當的與爬蟲溝通;“正常情況下”可以讓搜尋引擎的結果不顯示特定檔案。
以下幾種情況是建議使用的:
- 網站還有未完成或需要測試時。
- 有網頁內容重複性太高時。
- 網站內有一些相對不重要的資訊,浪費資源。
- 擁有機密檔案。
限制
他網有連結到設置封鎖的網頁,索引還是會被建立。
只是要自己的網頁不要出現在搜尋引擎上就請不要用這個方法,就算你使用 robots.txt 來限制,只要有別的網頁有說明文字指向你,那麼即使爬蟲未造訪這裡,也會被建立成索引。以下提供其他的方法給大家:密碼保護、noindex。不是所有的搜尋引擎都會支援。
不同的檢索器會自行決定要不要遵守,所以並不是強制性的。(Googlebot是好寶寶他會)不同檢索器語法的使用不一定相同。
我們平時熟知的大宗搜尋引擎都聽得懂,但就是有人會理解成不同的意思,這時候我們就必須應材施教了。
實作
基本規則
一開始先介紹一些基本的規範、格式~
- 一個網站只能存在一個 robots.txt 檔案。
- 檔名只能是 robots.txt ,不能當手遊的名字一樣亂取…PikaChiu(喂🤭
- 檔案要放在根目錄。
建立檔案並新增規則
第一步先用編輯器建立一個名叫 robots.txt 的文字檔,這邊要注意的是不要用文書處理軟體,人家說有可能會有問題。
再來就是重頭戲了,告訴你用三個單字搞定
- User_Agent: 爬蟲的名字,例如:Googlebot。
- Allow: 允許人家“可以”爬的。
- Disallow: “不同意”人家進來爬的。
好了教完了😂😂😂
範例
用一些範例來講解,大家應該就可以很快上手。